
Category: coreboot
No-microcode ROMs available in next Libreboot release (new stable release soon!)
coreboot versions 4.20 and 4.20.1 have been released
coreboot 4.20
The 4.20 release was done on May 15, 2023. Unfortunately, a licensing issue was found immediately after the release was completed, and it was decided to hold the release until that was fixed. The 4.20.1 release contains 4.20 plus that single additional fix.
Please do not use the 4.20 tag, and use the 4.20.1 git tag instead. The 4.20_branch will contain all code for 4.20, 4.20.1, and any further changes required for this release.
The tarballs for the 4.20.1 release may be downloaded from https://coreboot.org/downloads.html. The original 4.20 tarballs are not available due to the incorrect licensing text.
The coreboot community has done a tremendous amount of work on the codebase over the last three and a half months. We’ve had over 1600 commits in that time period, doing ongoing cleanup and improvement.
It can be hard to remember at times how much the codebase really has improved, but looking back at coreboot code from previous years, it’s really impressive the changes that have happened. We’d like to thank everyone who has been involved in these changes. It’s great to work with everyone involved, from the people who make the small cleanup patches and review all of the incoming changes to the people working on new chipsets and SoCs. We’d additionally like to thank all of those individuals who make the effort to become involved and report issues or push even a single patch to fix a bug that they’ve noticed.
Many thanks to everyone involved!
We plan to get the 4.21 release done in mid August, 2023.
Significant or interesting changes
cpu/mp_init.c: Only enable CPUs once they execute code
On some systems the BSP cannot know how many CPUs are present in the system. A typical use case is a multi socket system. Setting the enable flag only on CPUs that actually exist makes it more flexible.
cpu/x86/smm: Add PCI resource store functionality
In certain cases data within protected memory areas like SMRAM could be leaked or modified if an attacker remaps PCI BARs to point within that area. Add support to the existing SMM runtime to allow storing PCI resources in SMRAM and then later retrieving them.
This helps prevent moving BARs around to get SMM to access memory in areas that shouldn’t be accessed.
acpi: Add SRAT x2APIC table support
For platforms using X2APIC mode add SRAT x2APIC table generation. This allows the setup of proper SRAT tables.
drivers/usb/acpi: Add USB _DSM method to enable/disable USB LPM per port
This patch supports projects to use _DSM to control USB3 U1/U2 transition per port.
More details can be found in https://web.archive.org/web/20230116084819/https://learn.microsoft.com/en-us/windows-hardware/drivers/bringup/usb-device-specific-method—dsm-
The ACPI and USB driver of linux kernel need corresponding functions to support this feature. Please see https://git.kernel.org/pub/scm/linux/kernel/git/mnyman/xhci.git/log/?h=port_check_acpi_dsm
drivers/efi: Add EFI variable store option support
Add a driver to read and write EFI variables stored in a region device. This is particularly useful for EDK2 as payload and allows it to reuse existing EFI tools to set/get options used by the firmware.
The write implementation is fault tolerant and doesn’t corrupt the variable store. A faulting write might result in using the old value even though a ‘newer’ had been completely written.
Implemented basic unit tests for header corruption, writing existing data and append new data into the store.
Initial firmware region state: Initially the variable store region isn’t formatted. Usually this is done in the EDK2 payload when no valid firmware volume could be found. It might be useful to do this offline or in coreboot to have a working option store on the first boot or when it was corrupted.
Performance improvements: Right now the code always checks if the firmware volume header is valid. This could be optimised by caching the test result in heap. For write operations it would be good to cache the end of the variable store in the heap as well, instead of walking the whole store. For read operations caching the entire store could be considered.
Reclaiming memory: The EFI variable store is append write only. To update an existing variable, first a new is written to the end of the store and then the previous is marked invalid. This only works on PNOR flash that allow to clear set bits, but keep cleared bits state. This mechanisms allows a fault tolerant write, but it also requires to “clean” the variable store from time to time. This cleaning would remove variables that have been marked “deleted”. Such cleaning mechanism in turn must be fault tolerant and thus must use a second partition in the SPI flash as backup/working region. For now, cleaning is done in coreboot.
Fault checking: The driver should check if a previous write was successful and if not mark variables as deleted on the next operation.
drivers/ocp/ewl: Add EWL driver for EWL type 3 error handling
Add EWL (Enhanced Warning Log) driver which handles Intel EWL HOB and prints EWL type 3 primarily associated with MRC training failures.
Toolchain updates
- Upgrade MPC from version 1.2.1 to 1.3.1
- Upgrade MPFR from version 4.1.1 to 4.2.0
- Upgrade CMake from version 3.25.0 to 3.26.3
- Upgrade LLVM from version 15.0.6 to 15.0.7
- Upgrade GCC from version 11.2.0 to 11.3.0
- Upgrade binutils from version 2.37 to 2.40
Additional coreboot changes
- Remove Yabits payload. Yabits is deprecated and archived.
- Add DDR2 support to Intel GM45 code.
- Fix superiotool compilation issues when using musl-libc.
- Drop the Python 2 package from the coreboot-sdk.
- Drop the Zephyr SDK from coreboot-sdk since the packaged version was quite old and wasn’t really used.
- Add inteltool support for the Intel “Emmitsburg” PCH.
- Work to improve cache hit percentage when rebuilding using ccache.
- Adding Sound-Open-Firmware drivers to chromebooks to enable audio on non-chrome operating systems.
- Improve and expand ACPI generation code.
- Fix some issues for the RISC-V code.
- Continue upstreaming the POWER9 architecture.
- Add documentation for SBOM (Software Bill of Materials).
- Add SimNow console logging support for AMD.
- Do initial work on Xeon SPR
- CMOS defaults greater than 128 bytes long now extend to bank 1.
New Mainboards
- Asrock: B75M-ITX
- Dell: Latitude E6400
- Google: Aurash
- Google: Boxy
- Google: Constitution
- Google: Gothrax
- Google: Hades
- Google: Myst
- Google: Screebo
- Google: Starmie
- Google: Taranza
- Google: Uldren
- Google: Yavilla
- HP: EliteBook 2170p
- Intel: Archer City CRB
- Intel: DQ67SW
- Protectli: VP2420
- Protectli: VP4630/VP4650
- Protectli: VP4670
- Siemens: MC EHL4
- Siemens: MC EHL5
- System76: lemp11
- System76: oryp10
- System76: oryp9
Removed Mainboards
- Intel Icelake U DDR4/LPDDR4 RVP
- Intel Icelake Y LPDDR4 RVP
- Scaleway TAGADA
Updated SoCs
- Removed soc/intel/icelake
Plans to move platform support to a branch
Intel Quark SoC & Galileo mainboard
The SoC Intel Quark is unmaintained and different efforts to revive it have so far failed. The only user of this SoC ever was the Galileo board.
Thus, to reduce the maintenance overhead for the community, support for the following components will be removed from the master branch and will be maintained on the release 4.20 branch.
- Intel Quark SoC
- Intel Galileo mainboard
Statistics from the 4.19 to the 4.20 release
- Total Commits: 1630
- Average Commits per day: 13.72
- Total lines added: 102592
- Average lines added per commit: 62.94
- Number of patches adding more than 100 lines: 128
- Average lines added per small commit: 37.99
- Total lines removed: 34824
- Average lines removed per commit: 21.36
- Total difference between added and removed: 67768
- Total authors: ~170
- New authors: ~35
Significant Known and Open Issues
Issues from the coreboot bugtracker: https://ticket.coreboot.org/
| Bug # | Subject |
| 478 | X200 booting Linux takes a long time with TSC |
| 474 | X200s crashes after graphic init with 8GB RAM |
| 457 | Haswell (t440p): CAR mem region conflicts with CBFS_SIZE > 8mb |
| 453 | Intel HDMI / DP Audio device not showing up after libgfxinit |
| 449 | ThinkPad T440p fail to start, continuous beeping & LED blinking |
| 448 | Thinkpad T440P ACPI Battery Value Issues |
| 446 | Optiplex 9010 No Post |
| 439 | Lenovo X201 Turbo Boost not working (stuck on 2,4GHz) |
| 427 | x200: Two battery charging issues |
| 414 | X9SAE-V: No USB keyboard init on SeaBIOS using Radeon RX 6800XT |
| 412 | x230 reboots on suspend |
| 393 | T500 restarts rather than waking up from suspend |
| 350 | I225 PCIe device not detected on Harcuvar |
| 327 | OperationRegion (OPRG, SystemMemory, ASLS, 0x2000) causes BSOD |
Embracing a New Era: 9elements and AMD Collaborate to Bring Open-Source Firmware to 4th Gen EPYC Server Systems

What is AMD openSIL?
Before we dive deeper, let's first clarify what openSIL is. openSIL, or open-source Silicon Initialization Library, is a library designed to enable host firmware solutions to boot modern AMD server platforms seamlessly across the product market segments at scale. AMD's openSIL is committed to becoming entirely open-source and provides an interface for the host firmware to call into, initializing the AMD silicon and booting up as a Proof-of-Concept on 4th Gen AMD EPYC CPU based platforms.9elements' Involvement
Over the past months, 9elements and AMD have collaborated closely to support AMD openSIL development. In addition, 9elements has assisted AMD in developing a host firmware solution based on coreboot. At the OCP Regional Summit, 9elements will showcase the AMD openSIL demo, where coreboot+AMD openSIL+LinuxBoot boots an AMD EPYC CPU-based platform.coreboot Support on Modern Server Platforms
This remarkable progress demonstrates the industry's shift towards open-source firmware. In the server market, it is now possible to boot all major SoCs - AMD, Intel, and Ampere - with open-source firmware. While coreboot nowadays support Intel and AMD SoCs, Ampere SoC currently rely on EDKII/TianoCore only. However, Dong Wei, Lead Standards Architect and Fellow at ARM, announced at ByteDance's Cloud FW Event in March that ARM is exploring solutions to have coreboot + LinuxBoot running on ARM-based systems. We anticipate more developments from ARM at the OCP Global Summit and the Open-Source Firmware Conference. In summary, the collaboration between 9elements and AMD represents a monumental development for the open-source firmware movement. The open-sourcing of AMD openSIL and its integration into coreboot will not only benefit AMD and 9elements but the entire open-source community. The shift towards open-source firmware solutions promises to usher in a new era of transparency and security within the industry, and this partnership is a significant stride towards realizing that vision. AMDs announcement: https://community.amd.com/t5/business/empowering-the-industry-with-open-system-firmware-amd-opensil/ba-p/599644Announcing coreboot release 4.19
coreboot 4.19 release
The 4.19 release was completed on the 16th of January 2023.
Since the last release, the coreboot project has merged over 1600 commits from over 150 authors. Of those authors, around 25 were first-time committers to the coreboot project.
As always, we are very grateful to all of the contributors for helping to keep the project going. The coreboot project is different from many open source projects in that we need to keep constantly updating the codebase to stay relevant with the latest processors and technologies. It takes constant effort to just stay afloat, let alone improve the codebase. Thank you very much to everyone who has contributed, both in this release and in previous times.
The 4.20 release is planned for the 20th of April, 2023.
Significant or interesting changes
Show all Kconfig options in saved config file; compress same
The coreboot build system automatically adds a ‘config’ file to CBFS that lists the exact Kconfig configuration that the image was built with. This is useful to reproduce a build after the fact or to check whether support for a specific feature is enabled in the image.
This file has been generated using the ‘savedefconfig’ Kconfig command, which generates the minimal .config file that is needed to produce the required config in a coreboot build. This is fine for reproduction, but bad when you want to check if a certain config was enabled, since many options get enabled by default or pulled in through another option’s ‘select’ statement and thus don’t show up in the defconfig.
Instead coreboot now includes a larger .config instead. In order to save some space, all of the comments disabling options are removed from the file, except for those included in the defconfig.
We can also LZMA compress the file since it is never read by firmware itself and only intended for later re-extraction via cbfstool, which always has LZMA support included.
Toolchain updates
- Upgrade LLVM from 15.0.0 to 15.0.6
- Upgrade CMake from 3.24.2 to 3.25.0
- Upgrade IASL from 20220331 to 20221020
- Upgrade MPFR from 4.1.0 to 4.1.1
Finished the conversion to ASL 2.0 syntax
Until recently, coreboot still contained lots of code using the legacy ASL syntax. However, all ASL code was ported over to make use of the ASL 2.0 syntax and from this point on new ASL code should make use of it.
Additional coreboot changes
- Significant work was done to enable and build-test clang builds.
- Added touchscreen power sequencing and runtime detection.
- A number of patches were added to clean up and improve SMBIOS.
- Work is in progress to unify and extend coreboot post codes.
- Clean up for header includes is in progress with help from IWYU.
- IOAPIC code has been reworked.
- Support was added to superiotool for the NCT6687D-W chip.
- Work is progressing to switch return values to enum cb_err instead of bool or other pass/fail indicators.
- Clang builds are now working for most boards and are being build-tested.
- 64-bit coreboot support is in progress and is working on a number ofplatforms.
- A driver for EC used on various Clevo laptops was added.
- Native Intel Lynxpoint code was added to replace the MRC.bin.
- Work continued for the process of adding ops structures to the devicetree.
- The crossgcc tool can now download the source packages, which are needed to build the coreboot toolchain, from coreboot’s own mirror if desired.
- A document with useful external resources related to firmware development was added at Documentation/external_docs.md.
New Mainboards
- AMD: Mayan for Phoenix SoC
- GIGABYTE: GA-H61M-DS2
- Google: Crystaldrift
- Google: Gladios
- Google: Dibbi
- Google: Gaelin
- Google: Marasov
- Google: Markarth
- Google: Omnigul
- Google: Voltorb
- Intel: Meteorlake-P RVP
- MSI: PRO Z690-A (WIFI)
- Siemens: MC_EHL3
- Star Labs: StarBook Mk VI (i3-1220P and i7-1260P)
- System76: darp8
- System76: galp6
Removed Mainboards
- AMD: Inagua
- AMD: Olive Hill
- AMD: Parmer
- AMD: Persimmon
- AMD: Southstation
- AMD: Thatcher
- AMD: Unionstation
- ASROCK: E350M1
- ASROCK: IMB-A180
- ASUS: A88XM-E
- ASUS: AM1I-A
- ASUS: F2A85-M
- ASUS: F2A85-M LE
- ASUS: F2A85-M PRO
- BAP: ODE_e20xx
- Biostar: A68N-5200
- Biostar: AM1ML
- ELMEX: pcm205400
- ELMEX: pcm205401
- GizmoSphere: Gizmo
- GizmoSphere: Gizmo2
- Google: Morthal
- HP: ABM
- HP: Pavilion m6 1035dx
- Jetway: NF81_T56N_LF
- Lenovo: AMD G505s
- LiPPERT: FrontRunner-AF aka ADLINK CoreModule2-GF
- LiPPERT: Toucan-AF aka cExpress-GFR (+W83627DHG SIO)
- MSI: MS-7721 (FM2-A75MA-E35)
- PC Engines: APU1
Updated SoCs
- Added soc/amd/glinda
- Renamed soc/amd/morgana to soc/amd/phoenix
- Removed cpu/amd/agesa/family14
- Removed cpu/amd/agesa/family15tn
- Removed cpu/amd/agesa/family16kb
Updated Chipsets
- Removed northbridge/amd/agesa/family14
- Removed northbridge/amd/agesa/family15tn
- Removed northbridge/amd/agesa/family16kb
- Removed southbridge/amd/agesa/hudson
- Removed southbridge/amd/cimx/sb800
Payloads
- Updated GRUB from 2.04 to 2.06
- Updated SeaBIOS 1.16.0 to 1.16.1
Plans to move platform support to a branch
Intel Icelake SoC & Icelake RVP mainboard
Intel Icelake is unmaintained and the only user of this platform ever was the Intel CRB (Customer Reference Board). From the looks of the code, it was never ready for production as only engineering sample CPUIDs are supported.
Intel Icelake code will be removed following 4.19 and any maintenance will be done on the 4.19 branch. This consists of the Intel Icelake SoC and Intel Icelake RVP mainboard.
Intel Quark SoC & Galileo mainboard
The SoC Intel Quark is unmaintained and different efforts to revive it failed. Also, the only user of this platform ever was the Galileo board.
Thus, to reduce the maintenance overhead for the community, support for the following components will be removed from the master branch and will be maintained on the release 4.20 branch.
- Intel Quark SoC
- Intel Galileo mainboard
Statistics from the 4.18 to the 4.19 release
- Total Commits: 1608
- Average Commits per day: 17.39
- Total lines added: 93786
- Average lines added per commit: 58.32
- Number of patches adding more than 100 lines: 80
- Average lines added per small commit: 38.54
- Total lines removed: 768014
- Total difference between added and removed: -674228
Significant Known and Open Issues
Issues from the coreboot bugtracker: https://ticket.coreboot.org/
| # | Subject |
| 449 | ThinkPad T440p fail to start, continuous beeping & LED blinking |
| 448 | Thinkpad T440P ACPI Battery Value Issues |
| 446 | Optiplex 9010 No Post |
| 445 | Thinkpad X200 wifi issue |
| 439 | Lenovo X201 Turbo Boost not working (stuck on 2,4GHz) |
| 427 | x200: Two battery charging issues |
| 414 | X9SAE-V: No USB keyboard init on SeaBIOS using Radeon RX 6800XT |
| 412 | x230 reboots on suspend |
| 393 | T500 restarts rather than waking up from suspend |
| 350 | I225 PCIe device not detected on Harcuvar |
| 327 | OperationRegion (OPRG, SystemMemory, ASLS, 0x2000) causes BSOD |
Announcing coreboot 4.18
coreboot 4.18 release
The 4.18 release was quite late, but was completed on October 16, 2022.
In the 4 months since the 4.17 release, the coreboot project has merged more than 1800 commits from over 200 different authors. Over 50 of those authors submitted their first patches.
Welcome and thank you to all of our new contributors, and of course the work of all of the seasoned contributors is greatly appreciated.
Significant or interesting changes
sconfig: Allow to specify device operations
Currently we only have runtime mechanisms to assign device operations to a node in our devicetree (with one exception: the root device). The most common method is to map PCI IDs to the device operations with a struct pci_driver. Another accustomed way is to let a chip driver assign them.
For very common drivers, e.g. those in soc/intel/common/blocks/, the PCI ID lists grew very large and are incredibly error-prone. Often, IDs are missing and sometimes IDs are added almost mechanically without checking the code for compatibility. Maintaining these lists in a central place also reduces flexibility.
Now, for onboard devices it is actually unnecessary to assign the device operations at runtime. We already know exactly what operations should be assigned. And since we are using chipset devicetrees, we have a perfect place to put that information.
This patch adds a simple mechanism to sconfig. It allows us to speci- fy operations per device, e.g.
device pci 00.0 alias system_agent on ops system_agent_ops end
The operations are given as a C identifier. In this example, we simply assume that a global struct device_operations system_agent_ops exists.
Set touchpads to use detect (vs probed) flag
Historically, ChromeOS devices have worked around the problem of OEMs using several different parts for touchpads/touchscreens by using a ChromeOS kernel-specific ‘probed’ flag (rejected by the upstream kernel) to indicate that the device may or may not be present, and that the driver should probe to confirm device presence.
Since release 4.18, coreboot supports detection for i2c devices at runtime when creating the device entries for the ACPI/SSDT tables, rendering the ‘probed’ flag obsolete for touchpads. Switch all touchpads in the tree from using the ‘probed’ flag to the ‘detect’ flag.
Touchscreens require more involved power sequencing, which will be done at some future time, after which they will switch over as well.
Add SBOM (Software Bill of Materials) Generation
Firmware is typically delivered as one large binary image that gets flashed. Since this final image consists of binaries and data from a vast number of different people and companies, it’s hard to determine what all the small parts included in it are. The goal of the software bill of materials (SBOM) is to take a firmware image and make it easy to find out what it consists of and where those pieces came from.
Basically, this answers the question, who supplied the code that’s running on my system right now? For example, buyers of a system can use an SBOM to perform an automated vulnerability check or license analysis, both of which can be used to evaluate risk in a product. Furthermore, one can quickly check to see if the firmware is subject to a new vulnerability included in one of the software parts (with the specified version) of the firmware.
Further reference: https://web.archive.org/web/20220310104905/https://blogs.gnome.org/hughsie/2022/03/10/firmware-software-bill-of-materials/
- Add Makefile.inc to generate and build coswid tags
- Add templates for most payloads, coreboot, intel-microcode, amd-microcode. intel FSP-S/M/T, EC, BIOS_ACM, SINIT_ACM, intel ME and compiler (gcc,clang,other)
- Add Kconfig entries to optionally supply a path to CoSWID tags instead of using the default CoSWID tags
- Add CBFS entry called SBOM to each build via Makefile.inc
- Add goswid utility tool to generate SBOM data
Additional coreboot changes
The following are changes across a number of patches, or changes worth noting, but not needing a full description.
- Allocator v4 is not yet ready, but received significant work.
- Console: create an smbus console driver
- pciexp_device: Numerous updates and fixes
- Update checkpatch to match Linux v5.19
- Continue updating ACPI to ASL 2.0 syntax
- arch/x86: Add a common romstage entry point
- Documentation: Add a list of acronyms
- Start hooking up ops in devicetree
- Large amounts of general code cleanup and improvement, as always
- Work to make sure all files have licenses
Payloads
EDK II (TianoCore)
coreboot uses TianoCore interchangeably with EDK II, and whilst the meaning is generally clear, it’s not the payload it uses. Consequentially, TianoCore has been renamed to EDK II (2).
The option to use the already deprecated CorebootPayloadPkg has been removed.
Recent changes to both coreboot and EDK means that UefiPayloadPkg seems to work on all hardware. It has been tested on:
- Intel Core 2nd, 3rd, 4th, 5th, 6th, 7th, 8th, 8th, 9th, 10th, 11th and 12th generation processors
- Intel Small Core BYT, BSW, APL, GLK and GLK-R processors
- AMD Stoney Ridge and Picasso
CorebootPayloadPkg can still be found here.
The recommended option to use is EDK2_UEFIPAYLOAD_MRCHROMEBOX as EDK2_UEFIPAYLOAD_OFFICIAL will no longer work on any SoC.
New Mainboards
- AMD Birman
- AMD Pademelon renamed from Padmelon
- Google Evoker
- Google Frostflow
- Google Gaelin4ADL
- Google Geralt
- Google Joxer
- Google Lisbon
- Google Magikarp
- Google Morthal
- Google Pujjo
- Google Rex 0
- Google Shotzo
- Google Skolas
- Google Tentacruel
- Google Winterhold
- Google Xivu
- Google Yaviks
- Google Zoglin
- Google Zombie
- Google Zydron
- MSI PRO Z690-A WIFI DDR4
- Siemens MC APL7
Removed Mainboards
- Google Brya4ES
Updated SoCs
- Added Intel Meteor Lake
- Added Mediatek Mt8188
- Renamed AMD Sabrina to Mendocino
- Added AMD Morgana
Plans for Code Deprecation
LEGACY_SMP_INIT
Legacy SMP init will be removed from the coreboot master branch immediately following this release. Anyone looking for the latest version of the code should find it on the 4.18 branch or tag.
This also includes the codepath for SMM_ASEG. This code is used to start APs and do some feature programming on each AP, but also set up SMM. This has largely been superseded by PARALLEL_MP, which should be able to cover all use cases of LEGACY_SMP_INIT, with little code changes. The reason for deprecation is that having 2 codepaths to do the virtually the same increases maintenance burden on the community a lot, while also being rather confusing.
Intel Icelake SoC & Icelake RVP mainboard
Intel Icelake is unmaintained. Also, the only user of this platform ever was the Intel CRB (Customer Reference Board). From the looks of it the code was never ready for production as only engineering sample CPUIDs are supported. This reduces the maintanence overhead for the coreboot project.
Intel Icelake code will be removed with release 4.19 and any maintenence will be done on the 4.19 branch. This consists of the Intel Icelake SoC and Intel Icelake RVP mainboard.
Intel Quark SoC & Galileo mainboard
The SoC Intel Quark is unmaintained and different efforts to revive it failed. Also, the only user of this platform ever was the Galileo board.
Thus, to reduce the maintanence overhead for the community, support for the following components will be removed from the master branch and will be maintained on the release 4.20 branch.
- Intel Quark SoC
- Intel Galileo mainboard
Statistics from commit d2d9021543 to f4c97ea131
- Total Commits: 1822
- Average Commits per day: 13.38
- Total lines added: 150578
- Average lines added per commit: 82.64
- Number of patches adding more than 100 lines: 128
- Average lines added per small commit: 38.44
- Total lines removed: 33849
- Average lines removed per commit: 18.58
- Total difference between added and removed: 116729
- Total authors: 202
- New authors: 52
Known Issues
A couple of issues were discovered immediately following the release that will be fixed in a follow-on point release in the upcoming weeks.
A pair of changes (CB:67754 + CB:67662) merged shortly before the 4.18 release have created an issue on Intel Apollo Lake platform boards which prevents SMM/SMI from functioning; this affects only Apollo Lake (but not Gemini Lake) devices. A fix has been identified and tested and will be available soon.
Another issue applies to all Intel-based boards with onboard I2C TPMs when verified boot is not enabled. The I2C buses don’t get initialized until after the TPM, causing timeouts, TPM initialization failures, and long boot times.
How We Fixed Reboot Loops on the Librem Mini
Firmware debugging is uniquely challenging, because most conventional software debugging tools aren’t available. With coreboot’s specialized tooling, support from the amazing community, and a little bit of creativity, we fixed a regression in coreboot 4.17 that caused reboot loops on the Librem Mini. When coreboot makes a new release, I rebase our Librem-specific patches onto […]
The post How We Fixed Reboot Loops on the Librem Mini appeared first on Purism.
[GSoC] Optimize Erase Function Selection, wrap-up
GSoC 2022 coding period is about to come to an end this week. It has been an enriching 12 weeks of reading old code, designing algorithms and structures, coding, testing, and hanging out over IRC! I’d like to take this opportunity to present my work and details on how it has impacted Flashrom. 🙂
You can find the complete list of commits I made during GSoC with this gerrit query. Some of the patches aren’t currently merged and are under review. In any case, you are most welcome to join the review (which will likely be very helpful for me).
Definitions
Let me clarify some terminologies used hereafter
- Region: A list of contiguous addresses on the chip
- Layout: List of regions
- Locked region: There are some regions on the chip that cannot be accessed directly or in some cases cannot be accessed at all.
- Page: The entire flash memory is divided into uniform pages that can be written on. You have to write on an entire page at once.
- Erase block/sector: According to each erase function, flash memory is divided into regions (not necessarily uniform sized) that can be erased. You have to erase an entire erase block at once. So each erase function has a different erase block layout.
- Sub-block: An erase block is a sub-block of another erase block if it is completely inside the latter.
- Homogenous erase layout: All erase blocks in a layout are of uniform size.
- Nonhomogenous erase layout: There might be erase blocks of varying sizes in this layout.
Need for this project
To change any 0 to a 1 in the contents of a NOR-flash chip, a full block of data needs to be erased. So to change a single byte, it is sometimes required to erase a whole block, which we’ll call erase overhead. Most flash chips support multiple erase-block sizes. Flashrom keeps a list of these sizes and ranges for each supported flash chip and maps them to internal erase functions. Most of these lists were sorted by ascending size. I added a simple test to ensure this and corrected the ones which gave errors.
Earlier, Flashrom tried all available erase functions for a flash chip during writes. Usually, only the first function was used, but if anything went wrong on the wire, or the programmer rejected a function, it falls back to the next. As the functions are sorted by size, this results in a minimum erase overhead.
However, if big portions of the flash contents are re-written, using the smallest erase block size results in transaction overhead, and also erasing bigger blocks at once often results in shorter erase times inside the flash chip.
So in a nutshell, the erase function selection in Flashrom was sequential, i.e. they started from the function with the smallest erase block and moved to the next one only in case of an error. This was inefficient in cases where bigger chunks of the flash had to be erased.
Current implementation
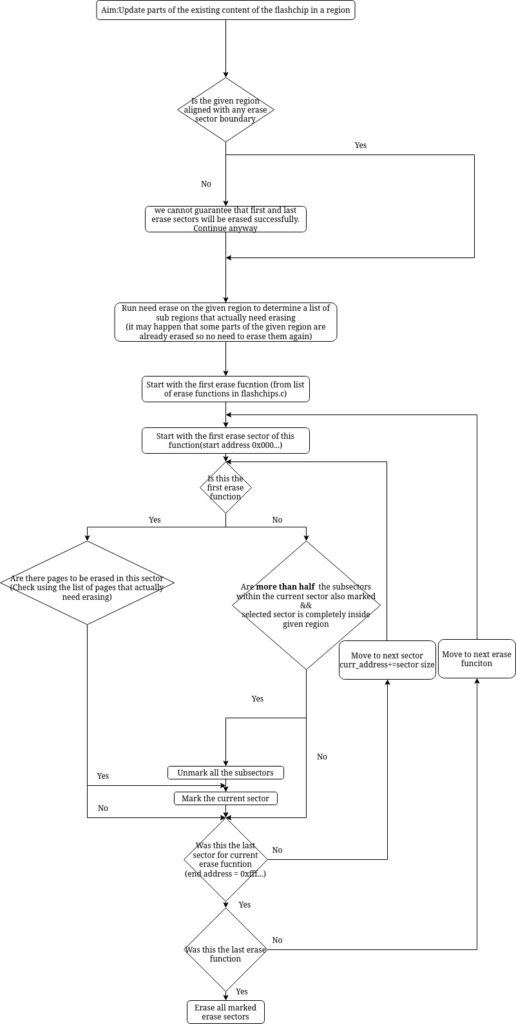
After rigorous discussion with my mentors and with the community, we decided on a look-ahead algorithm for selecting the erase functions or the erase blocks to be more precise. From the layout of erase blocks as seen by different erase functions, we make an optimal selection.
We start with the first erase function (remember this erase function has the smallest erase blocks) and mark those blocks which lie completely inside the region to be erased. Then moving on to subsequent erase layouts and marking those erase blocks that have more than half of the sub-blocks marked and then unmarking the marked sub-blocks. Finally, erase all the marked erase blocks. This strategy ensures that if we have a large contiguous region to be erased then we would use an appropriately large erase function to erase it.
The above-mentioned strategy had some challenges and required a few tweaks:
- The region to be erased may not be aligned to any erase blocks. This could be easily overcome by extending the ‘to be erased’ region to align it with some erase block.
- The above solution of extending the region brought a new challenge – the newly aligned region might overlap with write-protected regions. In this case, the erase function would fail to erase the erase block containing this region.
- It may happen that some erase functions are not supported by the programmer. This would lead to catastrophic failure. To this end, we thought of first getting a list of erase functions supported by the programmer and then running the algorithm on this subset of erase functions.
So with this, we were all set to begin the implementation of the algorithm. Or so I thought. Flashrom had stored information regarding the erase layout in a nested format which was very difficult to use so I had to flatten them out and fit them in a data structure that would give me quick information about sub-blocks as well. 😮💨
For a better understanding of the algorithm, I made the following flowchart.
Testing
Testing on hardware is difficult because you need all the different chips and programmers and test on each one of them to be sure that your code is working correctly. On top of that, identifying all possible scenarios adds to the burden. This definitely takes a lot of time and effort and my mentors and the community is helping a lot with it.
The current progress of testing can be seen here. Feel free to suggest more cases and help with the testing. It will definitely help a lot.
Future work
Definitely, the code or algorithm isn’t fully optimized and can be improved further. Also one can fix the progress bar feature to Flashrom, which got broken due to my code😅.
Acknowledgments
I’d like to thank Thomas Heijligen and Simon Buhrow for being excellent mentors, Nico for providing constant code reviews and giving regular inputs, and everyone in the Flashrom community for being helpful and friendly.
PureBoot’s Powerful Recovery Console
Normally when we talk about our high-security boot firmware PureBoot, it’s in the context of the advanced tamper detection it adds to a system. For instance, recently we added the ability to detect tampering even in the root file system. While that’s a critical benefit PureBoot provides over our default coreboot firmware, it also provides […]
The post PureBoot’s Powerful Recovery Console appeared first on Purism.
Announcing coreboot 4.17
coreboot 4.17
The coreboot 4.17 release was done on June 3, 2022.
Since the 4.16 release, we’ve had over 1300 new commits by around 150 contributors. Of those people, roughly 15 were first-time contributors.
As always, we appreciate everyone who has contributed and done the hard work to make the coreboot project successful.
Major Bugfixes in this release
New Mainboards
- Clevo L140MU / L141MU / L142MU
- Dell Precision T1650
- Google Craask
- Google Gelarshie
- Google Kuldax
- Google Mithrax
- Google Osiris
- HP Z220 CMT Workstation
- Star Labs LabTop Mk III (i7-8550u)
- Star Labs LabTop Mk IV (i3-10110U and i7-10710U)
- Star Labs Lite Mk III (N5000)
- Star Labs Lite Mk IV (N5030)
Removed Mainboards
- Google Deltan
- Google Deltaur
Significant or interesting changes
These changes are a few that were selected as a sampling of particularly interesting commits.
CBMEM init hooks changed
Instead of having per stage x_CBMEM_INIT_HOOK, we now have only 2 hooks:
- CBMEM_CREATION_HOOK: Used only in the first stage that creates cbmem, typically romstage. For instance code that migrates data from cache as ram to dram would use this hook.
- CBMEM_READY_HOOK: Used in every stage that has cbmem. An example would be initializing the cbmem console by appending to what previous stages logged. The reason for this change is improved flexibility with regards to which stage initializes cbmem.
Payloads
- SeaBIOS: Update stable release from 1.14.0 to 1.16.0
- iPXE: Update stable release from 2019.3 to 2022.1
- Add “GRUB2 atop SeaBIOS” aka “SeaGRUB” option, which builds GRUB2 as a secondary payload for SeaBIOS with GRUB2 set as the default boot entry. This allows GRUB2 to use BIOS callbacks provided by SeaBIOS as a fallback method to access hardware that the native GRUB2 payload cannot access.
- Add option to build SeaBIOS and GRUB2 as secondary payloads
- Add new coreDOOM payload. See commit message below.
payloads/external: Add support for coreDOOM payload
coreDOOM is a port of DOOM to libpayload, based on the doomgeneric source port. It renders the game to the coreboot linear framebuffer, and loads WAD files from CBFS.
cpu/x86/smm_module_load: Rewrite setup_stub
This code was hard to read as it did too much and had a lot of state to keep track of.
It also looks like the staggered entry points were first copied and only later the parameters of the first stub were filled in. This means that only the BSP stub is actually jumping to the permanent smihandler. On the APs the stub would jump to wherever c_handler happens to point to, which is likely 0. This effectively means that on APs it’s likely easy to have arbitrary code execution in SMM which is a security problem.
Note: This patch fixes CVE-2022-29264 for the 4.17 release.
cpu/x86/smm_module_loader.c: Rewrite setup
This code is much easier to read if one does not have to keep track of mutable variables.
This also fixes the alignment code on the TSEG smihandler setup code. It was aligning the code upwards instead of downwards which would cause it to encroach a part of the save state.
cpu/x86/smm: Add sinkhole mitigation to relocatable smmstub
The sinkhole exploit exists in placing the lapic base such that it messes with GDT. This can be mitigated by checking the lapic MSR against the current program counter.
cpu/x86/64bit: Generate static page tables from an assembly file
This removes the need for a tool to generate simple identity pages. Future patches will link this page table directly into the stages on some platforms so having an assembly file makes a lot of sense.
This also optimizes the size of the page of each 4K page by placing the PDPE_table below the PDE.
cpu/x86/smm,lib/cbmem_console: Enable CBMEMC when using DEBUG_SMI
This change will allow the SMI handler to write to the cbmem console buffer. Normally SMIs can only be debugged using some kind of serial port (UART). By storing the SMI logs into cbmem we can debug SMIs using ‘cbmem -1’. Now that these logs are available to the OS we could also verify there were no errors in the SMI handler.
Since SMM can write to all of DRAM, we can’t trust any pointers provided by cbmem after the OS has booted. For this reason we store the cbmem console pointer as part of the SMM runtime parameters. The cbmem console is implemented as a circular buffer so it will never write outside of this area.
security/tpm/crtm: Add a function to measure the bootblock on SoC level
On platforms where the bootblock is not included in CBFS anymore because it is part of another firmware section (IFWI or a different CBFS), the CRTM measurement fails.
This patch adds a new function to provide a way at SoC level to measure the bootblock. Following patches will add functionality to retrieve the bootblock from the SoC related location and measure it from there. In this way the really executed code will be measured.
soc/amd/common/block/psp: Add platform secure boot support
Add Platform Secure Boot (PSB) enablement via the PSP if it is not already enabled. Upon receiving psb command, PSP will program PSB fuses as long as BIOS signing key token is valid. Refer to the AMD PSB user guide doc# 56654, Revision# 1.00. Unfortunately this document is only available with NDA customers.
drivers/intel/fsp2_0: Add native implementation for FSP Debug Handler
This patch implements coreboot native debug handler to manage the FSP event messages.
‘FSP Event Handlers’ feature introduced in FSP to generate event messages to aid in the debugging of firmware issues. This eliminates the need for FSP to directly write debug messages to the UART and FSP might not need to know the board related UART port configuration. Instead FSP signals the bootloader to inform it of a new debug message. This allows the coreboot to provide board specific methods of reporting debug messages, example: legacy UART or LPSS UART etc.
This implementation has several advantages as:
- FSP relies on XIP ‘DebugLib’ driver even while printing FSP-S debug messages, hence, without ROM being cached, post ‘romstage’ would results into sluggish boot with FSP debug enabled. This patch utilities coreboot native debug implementation which is XIP during FSP-M and relocatable to DRAM based resource for FSP-S.
- This patch simplifies the FSP DebugLib implementation and remove the need to have serial port library. Instead coreboot ‘printk’ can be used for display FSP serial messages. Additionally, unifies the debug library between coreboot and FSP.
- This patch is also useful to get debug prints even with FSP non-serial image (refer to ‘Note’ below) as FSP PEIMs are now leveraging coreboot debug library instead FSP ‘NULL’ DebugLib reference for release build.
- Can optimize the FSP binary size by removing the DebugLib dependency from most of FSP PEIMs, for example: on Alder Lake FSP-M debug binary size is reduced by ~100KB+ and FSP-S debug library size is also reduced by ~300KB+ (FSP-S debug and release binary size is exactly same with this code changes). The total savings is ~400KB for each FSP copy, and in case of Chrome AP firmware with 3 copies, the total savings would be 400KB * 3 = ~1.2MB.
Note: Need to modify FSP source code to remove ‘MDEPKG_NDEBUG’ as compilation flag for release build and generate FSP binary with non-NULL FSP debug wrapper module injected (to allow FSP event handler to execute even with FSP non-serial image) in the final FSP.fd.
security/tpm: Add vendor-specific tis functions to read/write TPM regs
In order to abstract bus-specific logic from TPM logic, the prototype for two vendor-specific tis functions are added in this patch. tis_vendor_read() can be used to read directly from TPM registers, and tis_vendor_write() can be used to write directly to TPM registers.
arch/x86: Add support for catching null dereferences through debug regs
This commit adds support for catching null dereferences and execution through x86’s debug registers. This is particularly useful when running 32-bit coreboot as paging is not enabled to catch these through page faults. This commit adds three new configs to support this feature: DEBUG_HW_BREAKPOINTS, DEBUG_NULL_DEREF_BREAKPOINTS and DEBUG_NULL_DEREF_HALT.
drivers/i2c/generic: Add support for i2c device detection
Add ‘detect’ flag which can be attached to devices which may or may not be present at runtime, and for which coreboot should probe the i2c bus to confirm device presence prior to adding an entry for it in the SSDT.
This is useful for boards which may utilize touchpads/touchscreens from multiple vendors, so that only the device(s) present are added to the SSDT. This relieves the burden from the OS to detect/probe if a device is actually present and allows the OS to trust the ACPI _STA value.
util/cbmem: Add FlameGraph-compatible timestamps output
Flame graphs are used to visualize hierarchical data, like call stacks. Timestamps collected by coreboot can be processed to resemble profiler-like output, and thus can be feed to flame graph generation tools.
Generating flame graph using https://github.com/brendangregg/FlameGraph:
cbmem -S > trace.txt FlameGraph/flamegraph.pl --flamechart trace.txt > output.svg
src/console/Kconfig: Add option to disable loglevel prefix
This patch adds an option to disable loglevel prefixes. This patch helps to achieve clear messages when low loglevel is used and very few messages are displayed on a terminal. This option also allows to maintain compatibility with log readers and continuous integration systems that depend on fixed log content.
If the code contains: printk(BIOS_DEBUG, “This is a debug message!\n”) it will show as: [DEBUG] This is a debug message! but if the Kconfig contains: CONFIG_CONSOLE_USE_LOGLEVEL_PREFIX=n the same message will show up as This is a debug message!
util/cbmem: add an option to append timestamp
Add an option to the cbmem utility that can be used to append an entry to the cbmem timestamp table from userspace. This is useful for bookkeeping of post-coreboot timing information while still being able to use cbmem-based tooling for processing the generated data.
-a | --add-timestamp ID: append timestamp with ID\n
Additional changes
The following are changes across a number of patches, or changes worth noting, but not needing a full description.
- As always, general documentation, code cleanup, and refactoring
- Remove doxygen config files and targets
- Get clang compile working for all x86 platforms
- Work on updating checkpatch to match the current Linux version
- Timestamps: Rename timestamps to make names more consistent
- Continue updating ACPI code to ASL 2.0
- Remove redundant or unnecessary headers from C files
- arch/x86/acpi_bert_storage.c: Use a common implementation
- Postcar stage improvements
- arch/x86/acpi: Consolidate POST code handling
- intel/common: Enable ROM caching in ramstage
- vendorcode/amd/agesa: Fix improper use of .data (const is important)
- sandybridge & gm45: Support setting PCI bars above 4G
Plans for Code Deprecation
Intel Icelake
Intel Icelake is unmaintained. Also, the only user of this platform ever was the CRB board. From the looks of it the code never was ready for production as only engineering sample CPUIDs are supported.
Thus, to reduce the maintanence overhead for the community, it is deprecated from this release on and support for the following components will be dropped with the release 4.19.
- Intel Icelake SoC
- Intel Icelake RVP mainboard
LEGACY_SMP_INIT
As of release 4.18 (August 2022) we plan to deprecate LEGACY_SMP_INIT. This also includes the codepath for SMM_ASEG. This code is used to start APs and do some feature programming on each AP, but also set up SMM. This has largely been superseded by PARALLEL_MP, which should be able to cover all use cases of LEGACY_SMP_INIT, with little code changes. The reason for deprecation is that having 2 codepaths to do the virtually the same increases maintenance burden on the community a lot, while also being rather confusing.
No platforms in the tree have any hardware limitations that would block migrating to PARALLEL_MP / a simple !CONFIG_SMP codebase.
Statistics
- Total Commits: 1305
- Average Commits per day: 13.42
- Total lines added: 51422
- Average lines added per commit: 39.40
- Number of patches adding more than 100 lines: 59
- Average lines added per small commit: 24.73
- Total lines removed: 66206
- Average lines removed per commit: 50.73
- Total difference between added and removed: -14784
- Total authors: 146
- New authors: 17