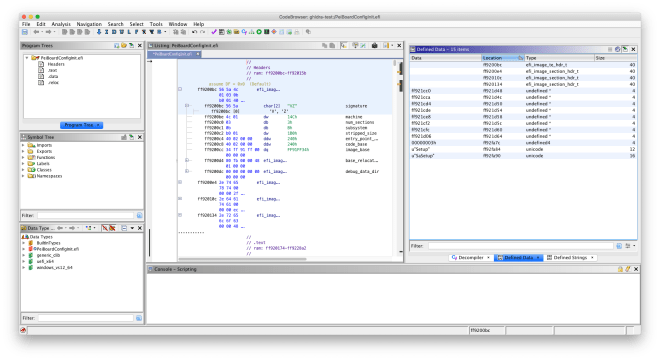
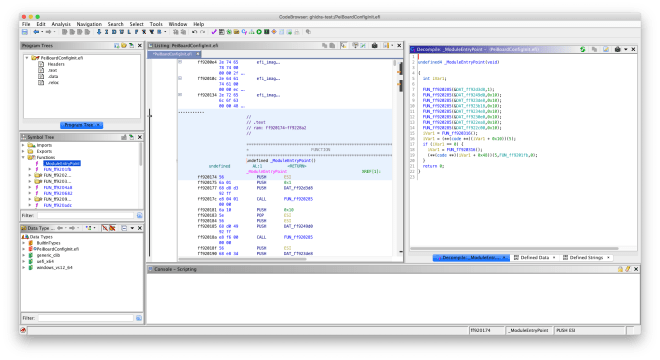
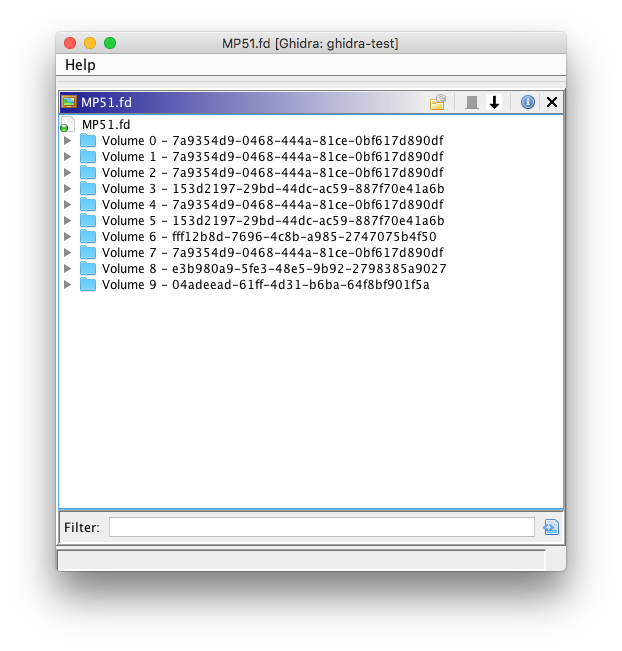
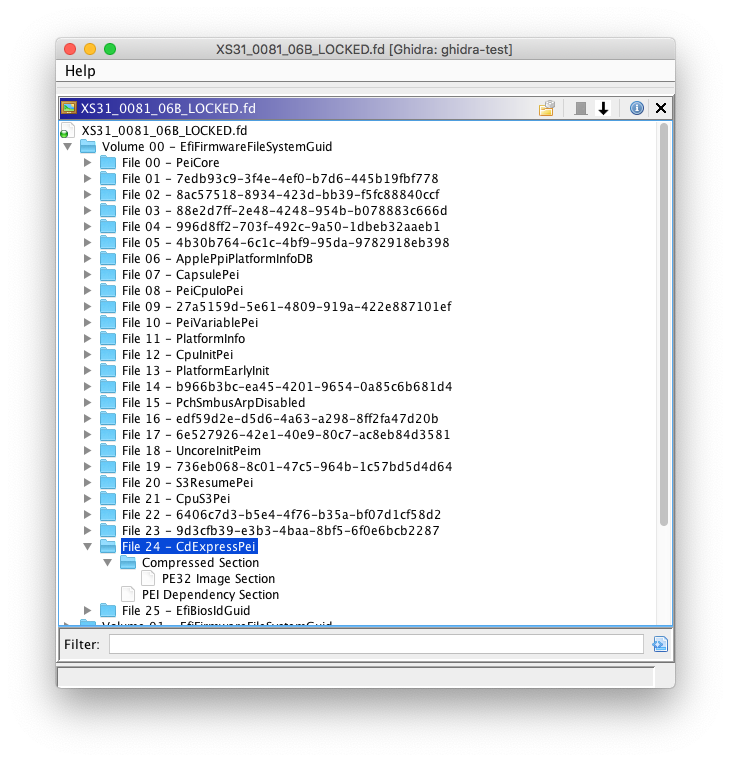
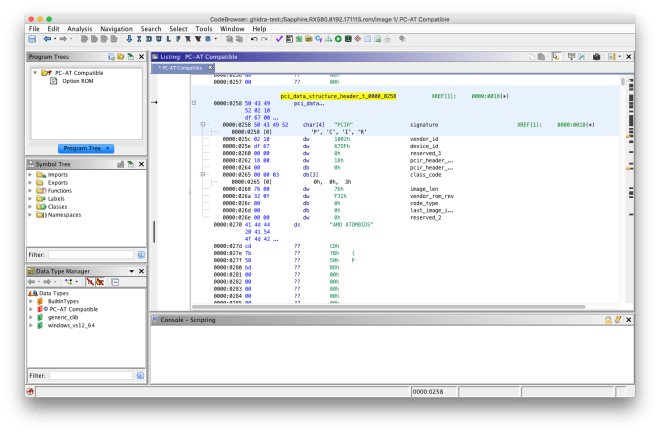
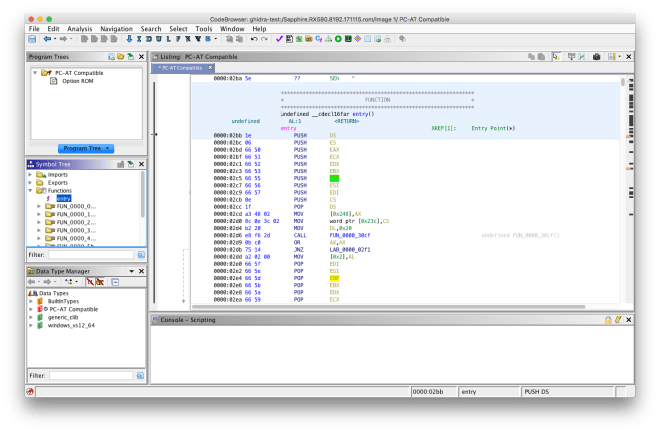
Hi everyone. The official programming period for GSoC 2019 is now over, and it’s time for final evaluations. I will use this post to summarize what I’ve worked on this summer, as well as how to use the Ghidra plugin.
The project is available on GitHub: https://github.com/al3xtjames/ghidra-firmware-utils
Project details
In my initial project proposal, I planned on writing various filesystem loaders (for hybrid PCI option ROMs, Intel flash descriptor images, coreboot File System images, and UEFI firmware volumes), a binary loader for legacy x86 PCI option ROMs, and a UEFI helper script. I ended up implementing all of these in the Ghidra plugin, and also worked on a UEFI Terse Executable binary loader. You can look at my previous blogposts to see my progress throughout the summer.
Here is a description of the components included in the project:
FS loaders allow files stored within binary images to be imported directly into Ghidra. The following FS loaders are implemented in this project:
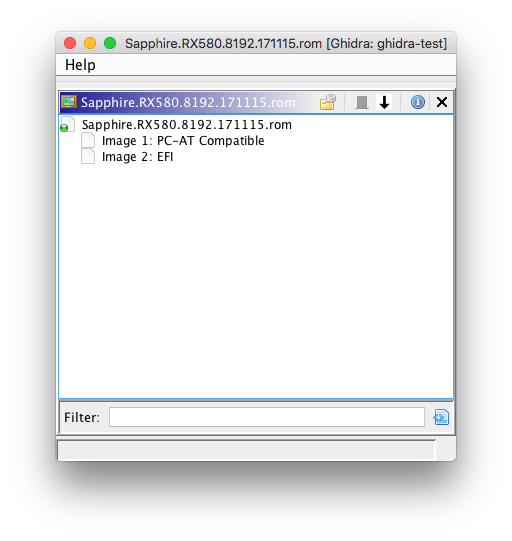
Hybrid PCI option ROM
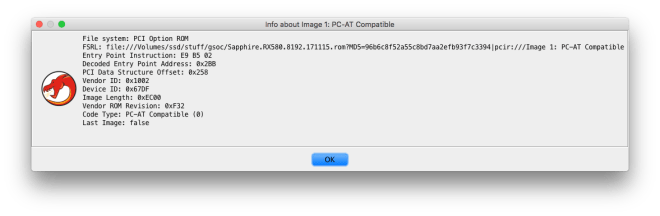
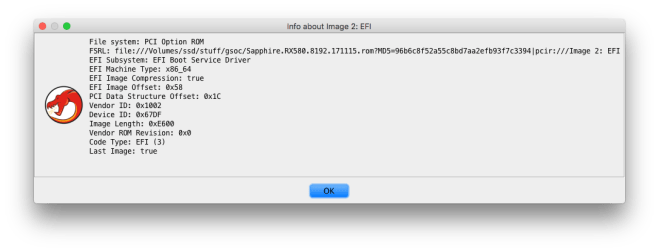
Some PCI option ROMs may contain multiple executable ROMs. This is usually used to support multiple firmware types (e.g. a video card with legacy BIOS VGA support and UEFI Graphics Output Protocol support). The FS loader allows each embedded executable ROM image to be imported.
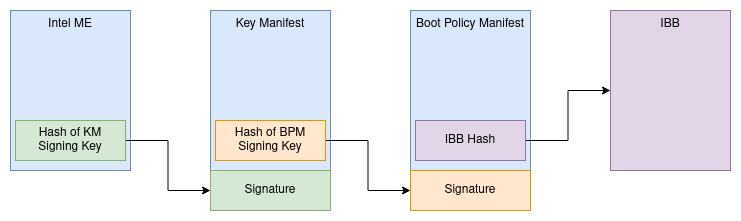
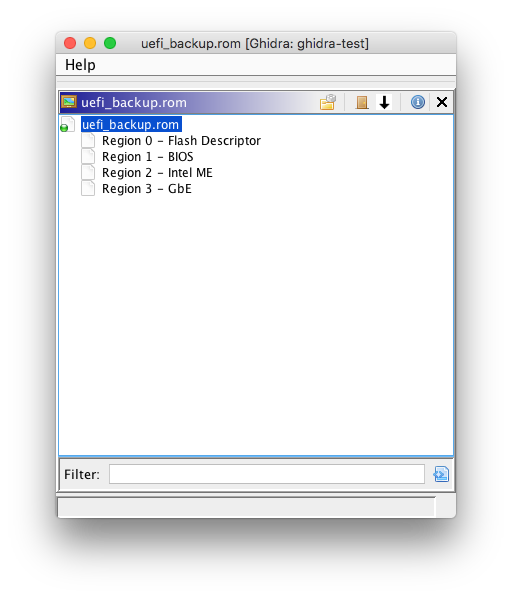
Intel firmware descriptor (IFD)
Recent Intel platforms have multiple regions on the SPI flash (used to store system firmware). The descriptor region describes the layout of these flash regions. The FS loader allows each flash region to be imported. Ghidra supports nested FS loaders, so other FS loaders (FMAP/CBFS or UEFI FV) can be used to parse certain regions, such as the BIOS region.
Flash Map (FMAP)
This is another standard for describing flash regions, used by coreboot and various Google devices. Like the IFD FS loader, this allows each defined flash region to be imported, and it can be used with other FS loaders (e.g. the COREBOOT region can be parsed with the CBFS loader).
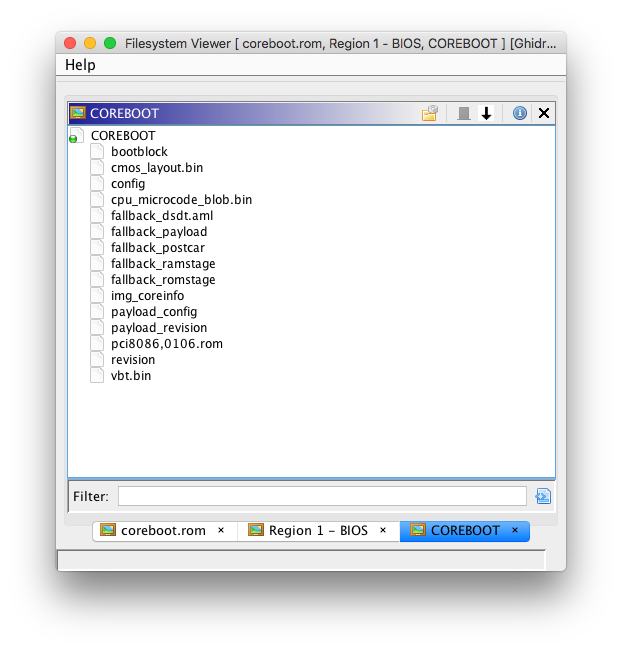
coreboot File System (CBFS)
coreboot uses a simple file system to store independent binaries and data files. The CBFS loader can be used to import each CBFS file for analysis; for example, PCI option ROMs stored as CBFS files can be imported. Optional CBFS file compression (LZ4/LZMA) is supported.
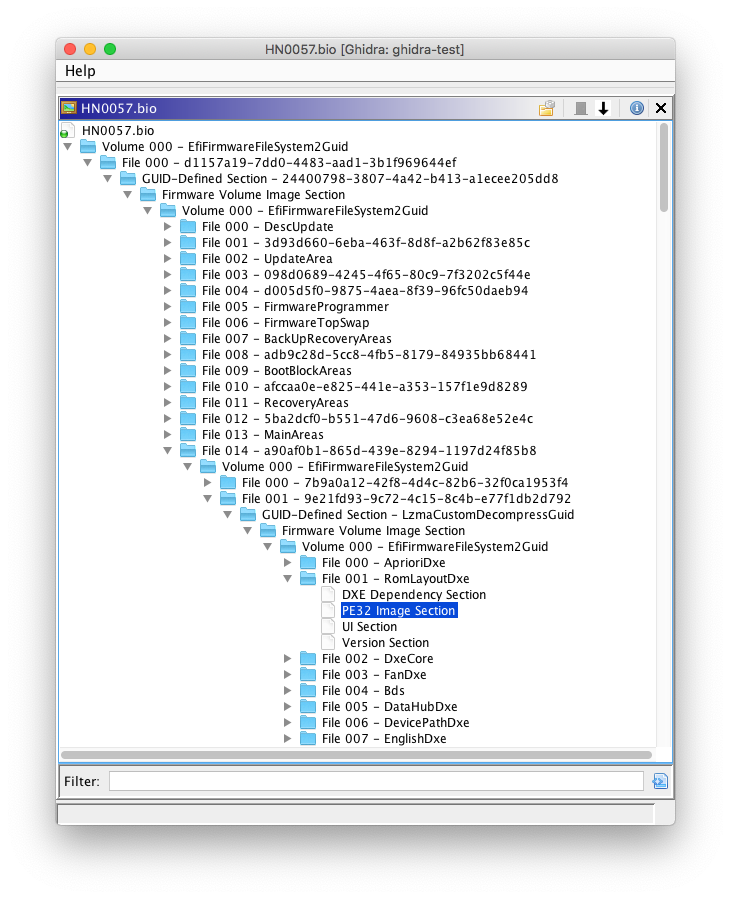
UEFI firmware volume (FV)/firmware file system (FFS)
UEFI firmware images use firmware volumes for storing firmware files, which may consist of multiple sections. The UEFI FV FS loader allows UEFI firmware volumes to be imported, including embedded firmware files/sections.
This project also implements a couple of binary loaders:
Legacy x86 option ROM
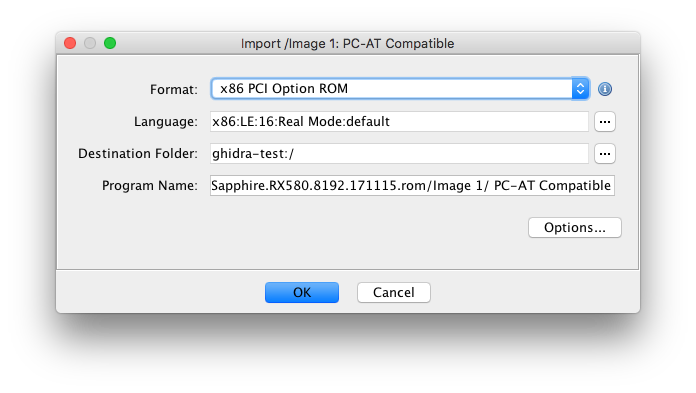
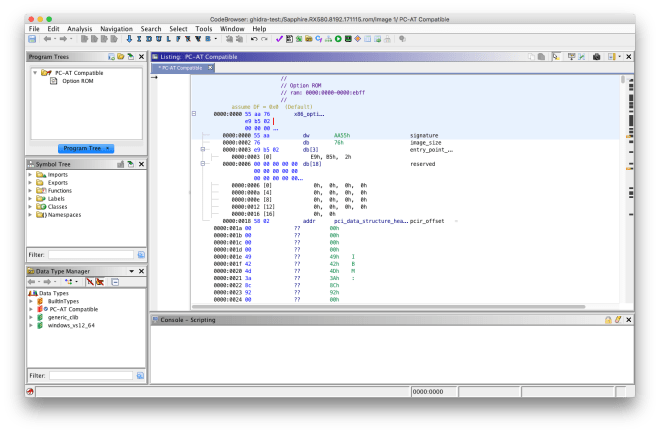
PCI option ROMs that target the x86 legacy BIOS contain a raw 16-bit executable image. They also have additional header fields, including a field with the entry point instruction. The binary loader resolves the entry point and specifies that 16-bit x86 disassembly should be used.
UEFI Terse Executable (TE)
UEFI binaries can use one of two executable formats: the Portable Executable (PE32) format (also used on Windows), and the Terse Executable (TE) format. Terse Executables are essentially simplified PE32 binaries – the numerous DOS/NT/optional headers are condensed into a single TE header, without any superfluous header fields. The binary loader resolves the entry point and defines memory blocks corresponding to the sections defined in the TE header.
Finally, a helper script for assisting with the analysis of UEFI binaries is
included. The UEFI helper script does the following:
- Imports a UEFI data type library
- Defines the entry point signature
- Searches for known EFI GUIDs in the .data/.text segments
- Attempts to locate global EFI table pointers (
gST/gBS/gRT) - Attempts to perform propagation of some EFI types to called functions
Project usage
Instructions for how to build and use the Ghidra plugin are included in the project’s README, but I’ll restate them here.
Building the plugin
Like other Ghidra plugins (and Ghidra itself), this project uses Gradle as the build system. Set the GHIDRA_INSTALL_DIR environment variable (point it to your Ghidra installation directory) and run gradle to build the plugin. Install the generated ZIP (in the dist directory) by selecting
File > Install Extensions in Ghidra, and then clicking the green plus icon.
Using the FS loaders
Load the specified input file into Ghidra (drag and drop or use File > Import File). Assuming the input file is supported by a FS loader, Ghidra should indicate that a container file was detected, and will allow you to batch import all enclosed files or view the file system.
Note that Ghidra does support parsing nested filesystems with multiple FS loaders. For example, UEFI firmware volumes in the BIOS region of an Intel firmware image can be parsed by first importing the Intel firmware image and then importing the BIOS region (select Import or Open File System in the right-click menu).
Using the UEFI helper script
After loading a UEFI executable (PE32 or TE), you can run the UEFI Helper script from the Script Manager window (under Window). Select UEFIHelper.java and click the green “Run Script” button.
Currently, the UEFI helper script assumes the entry point matches the standard driver/application signature (with EFI_HANDLE and EFI_SYSTEM_TABLE * parameters). SEC/PEI/SMM modules have different entry point parameters, which will have to be manually specified.
Future work
While my work for GSoC 2019 is complete, I think the following additions would be useful for this project (and UEFI reverse-engineering in general):
Processor module for disassembling EFI Byte Code (EBC)
EFI Byte Code is a byte code format used for platform-independent UEFI applications/drivers. Ghidra currently doesn’t support the EBC virtual machine architecture. Fortunately, it is possible to add support for an architecture by creating a SLEIGH processor specification.
Upstreamed Terse Executable loader
As previously described, TE binaries are very similar to PE binaries. Ghidra already has parsers for the data directory and section header structures, which are present in both PE and TE binaries. My TE loader had to reimplement these parsers, as the existing parsers depended on the NT header, which isn’t present in TE binaries. Removing the NT header dependency from the data directory/section header parsers would allow Ghidra’s existing parsers to be reused by the TE loader. This would also make it easier to upstream the TE loader.
Support for SEC/PEI/SMM modules (UEFI helper script)
Instead of assuming the entry point parameters, the script could prompt the user to select the module type, or somehow retrieve the module type from the FFS header (if the FS loader was used).
Additional GUID heuristics (UEFI helper script)
The script could locate calls to EFI_BOOT_SERVICES/EFI_RUNTIME_SERVICES functions with GUID parameters and automatically apply the EFI_GUID data type.
Protocol database (UEFI helper script)
Similar to the existing GUID->name database (imported from UEFITool), a database for mapping protocol definitions to the structure name could be created. The script could use this database to automatically apply the correct protocol structure type in calls to LocateProtocol/etc.
Very basic dependency graph (inspired by this UEFITool issue) (UEFI helper script)
The script could locate all calls to protocol consumption/production functions in EFI_BOOT_SERVICES (such as LocateProtocol, InstallProtocol, etc) and use this to generate a basic overview of the protocols used by the current UEFI binary.
Acknowledgements
I would like to thank my mentors Martin Roth and Raul Rangel for their continued assistance during the past 12 weeks. This has been a great opportunity, and it certainly wouldn’t have been possible without their help. I look forward to contributing to coreboot and other related projects (including Ghidra) in the future.

 We are happy to announce that the Converged Security Suite got some major updates and arrived at release version 2.6.0. Not only does this release provide new features, but also comes with a new look! Thanks to the design team at 9elements.com we do have our own logo now.
We are happy to announce that the Converged Security Suite got some major updates and arrived at release version 2.6.0. Not only does this release provide new features, but also comes with a new look! Thanks to the design team at 9elements.com we do have our own logo now.